![]()
Accurate & Verified 2024 New Databricks-Certified-Data-Engineer-Associate Answers As Experienced in the Actual Test!
Databricks-Certified-Data-Engineer-Associate Certification Sample Questions certification Exam
To prepare for the certification exam, candidates can take advantage of various study resources, including online courses, study guides, and practice exams. The GAQM website also provides a detailed exam blueprint that outlines the topics and subtopics covered in the exam. Candidates can use this blueprint to create a study plan and focus their preparation efforts on the areas where they need the most improvement.
The GAQM Databricks-Certified-Data-Engineer-Associate exam is a comprehensive test of an individual's knowledge of Databricks and its related technologies. It evaluates the ability of candidates to design, build, and maintain data pipelines using Databricks. Databricks Certified Data Engineer Associate Exam certification is ideal for data engineers, data architects, and data scientists who want to showcase their skills and knowledge in working with Databricks. Earning the certification can help individuals advance their careers and lead to better job opportunities and higher salaries.
NEW QUESTION # 20
A data engineer has developed a data pipeline to ingest data from a JSON source using Auto Loader, but the engineer has not provided any type inference or schema hints in their pipeline. Upon reviewing the data, the data engineer has noticed that all of the columns in the target table are of the string type despite some of the fields only including float or boolean values.
Which of the following describes why Auto Loader inferred all of the columns to be of the string type?
- A. All of the fields had at least one null value
- B. Auto Loader only works with string data
- C. There was a type mismatch between the specific schema and the inferred schema
- D. Auto Loader cannot infer the schema of ingested data
- E. JSON data is a text-based format
Answer: E
NEW QUESTION # 21
Which of the following is hosted completely in the control plane of the classic Databricks architecture?
- A. Databricks Filesystem
- B. Driver node
- C. JDBC data source
- D. Databricks web application
- E. Worker node
Answer: B
NEW QUESTION # 22
An engineering manager uses a Databricks SQL query to monitor ingestion latency for each data source. The manager checks the results of the query every day, but they are manually rerunning the query each day and waiting for the results.
Which of the following approaches can the manager use to ensure the results of the query are updated each day?
- A. They can schedule the query to refresh every 1 day from the query's page in Databricks SQL.
- B. They can schedule the query to refresh every 12 hours from the SQL endpoint's page in Databricks SQL.
- C. They can schedule the query to refresh every 1 day from the SQL endpoint's page in Databricks SQL.
- D. They can schedule the query to run every 12 hours from the Jobs UI.
- E. They can schedule the query to run every 1 day from the Jobs UI.
Answer: A
Explanation:
Explanation
https://docs.databricks.com/en/sql/user/queries/schedule-query.html
NEW QUESTION # 23
Which of the following is hosted completely in the control plane of the classic Databricks architecture?
- A. Driver node
- B. Databricks web application
- C. Databricks Filesystem
- D. JDBC data source
- E. Worker node
Answer: B
Explanation:
Explanation
In the classic Databricks architecture, the control plane includes components like the Databricks web application, the Databricks REST API, and the Databricks Workspace. These components are responsible for managing and controlling the Databricks environment, including cluster provisioning, notebook management, access control, and job scheduling. The other options, such as worker nodes, JDBC data sources, Databricks Filesystem (DBFS), and driver nodes, are typically part of the data plane or the execution environment, which is separate from the control plane. Worker nodes are responsible for executing tasks and computations, JDBC data sources are used to connect to external databases, DBFS is a distributed file system for data storage, and driver nodes are responsible for coordinating the execution of Spark jobs.
NEW QUESTION # 24
A data engineering team has two tables. The first table march_transactions is a collection of all retail transactions in the month of March. The second table april_transactions is a collection of all retail transactions in the month of April. There are no duplicate records between the tables.
Which of the following commands should be run to create a new table all_transactions that contains all records from march_transactions and april_transactions without duplicate records?
- A. CREATE TABLE all_transactions AS
SELECT * FROM march_transactions
INTERSECT SELECT * from april_transactions; - B. CREATE TABLE all_transactions AS
SELECT * FROM march_transactions
INNER JOIN SELECT * FROM april_transactions; - C. CREATE TABLE all_transactions AS
SELECT * FROM march_transactions
UNION SELECT * FROM april_transactions; - D. CREATE TABLE all_transactions AS
SELECT * FROM march_transactions
MERGE SELECT * FROM april_transactions; - E. CREATE TABLE all_transactions AS
SELECT * FROM march_transactions
OUTER JOIN SELECT * FROM april_transactions;
Answer: C
Explanation:
Explanation
To create a new table all_transactions that contains all records from march_transactions and april_transactions without duplicate records, you should use the UNION operator, as shown in option B. This operator combines the result sets of the two tables while automatically removing duplicate records.
NEW QUESTION # 25
A Delta Live Table pipeline includes two datasets defined using STREAMING LIVE TABLE. Three datasets are defined against Delta Lake table sources using LIVE TABLE.
The table is configured to run in Production mode using the Continuous Pipeline Mode.
Assuming previously unprocessed data exists and all definitions are valid, what is the expected outcome after clicking Start to update the pipeline?
- A. All datasets will be updated at set intervals until the pipeline is shut down. The compute resources will be deployed for the update and terminated when the pipeline is stopped.
- B. All datasets will be updated once and the pipeline will shut down. The compute resources will be terminated.
- C. All datasets will be updated once and the pipeline will shut down. The compute resources will persist to allow for additional testing.
- D. All datasets will be updated once and the pipeline will persist without any processing. The compute resources will persist but go unused.
- E. All datasets will be updated at set intervals until the pipeline is shut down. The compute resources will persist to allow for additional testing.
Answer: E
Explanation:
Explanation
In a Delta Live Table pipeline running in Continuous Pipeline Mode, when you click Start to update the pipeline, the following outcome is expected: All datasets defined using STREAMING LIVE TABLE and LIVE TABLE against Delta Lake table sources will be updated at set intervals. The compute resources will be deployed for the update process and will be active during the execution of the pipeline. The compute resources will be terminated when the pipeline is stopped or shut down. This mode allows for continuous and periodic updates to the datasets as new data arrives or changes in the underlying Delta Lake tables occur. The compute resources are provisioned and utilized during the update intervals to process the data and perform the necessary operations.
NEW QUESTION # 26
A data engineer has a Job with multiple tasks that runs nightly. Each of the tasks runs slowly because the clusters take a long time to start.
Which of the following actions can the data engineer perform to improve the start up time for the clusters used for the Job?
- A. They can configure the clusters to be single-node
- B. They can use jobs clusters instead of all-purpose clusters
- C. They can use endpoints available in Databricks SQL
- D. They can configure the clusters to autoscale for larger data sizes
- E. They can use clusters that are from a cluster pool
Answer: B
NEW QUESTION # 27
A data analysis team has noticed that their Databricks SQL queries are running too slowly when connected to their always-on SQL endpoint. They claim that this issue is present when many members of the team are running small queries simultaneously. They ask the data engineering team for help. The data engineering team notices that each of the team's queries uses the same SQL endpoint.
Which of the following approaches can the data engineering team use to improve the latency of the team's queries?
- A. They can turn on the Serverless feature for the SQL endpoint and change the Spot Instance Policy to
"Reliability Optimized." - B. They can turn on the Serverless feature for the SQL endpoint.
- C. They can turn on the Auto Stop feature for the SQL endpoint.
- D. They can increase the cluster size of the SQL endpoint.
- E. They can increase the maximum bound of the SQL endpoint's scaling range.
Answer: D
Explanation:
Explanation
When many users are running small queries simultaneously on a SQL endpoint, the database can become overloaded, causing slow query execution times. By increasing the cluster size of the SQL endpoint, the database can handle more simultaneous queries, resulting in faster query execution times.
NEW QUESTION # 28
A data engineer needs to create a table in Databricks using data from their organization's existing SQLite database.
They run the following command:
Which of the following lines of code fills in the above blank to successfully complete the task?
- A. sqlite
- B. autoloader
- C. DELTA
- D. org.apache.spark.sql.sqlite
- E. org.apache.spark.sql.jdbc
Answer: E
Explanation:
Explanation
CREATE TABLE new_employees_table
USING JDBC
OPTIONS (
url "<jdbc_url>",
dbtable "<table_name>",
user '<username>',
password '<password>'
) AS
SELECT * FROM employees_table_vw
https://docs.databricks.com/external-data/jdbc.html#language-sql
NEW QUESTION # 29
A data analysis team has noticed that their Databricks SQL queries are running too slowly when connected to their always-on SQL endpoint. They claim that this issue is present when many members of the team are running small queries simultaneously. They ask the data engineering team for help. The data engineering team notices that each of the team's queries uses the same SQL endpoint.
Which of the following approaches can the data engineering team use to improve the latency of the team's queries?
- A. They can increase the maximum bound of the SQL endpoint's scaling range.
- B. They can turn on the Serverless feature for the SQL endpoint and change the Spot Instance Policy to
"Reliability Optimized." - C. They can turn on the Serverless feature for the SQL endpoint.
- D. They can turn on the Auto Stop feature for the SQL endpoint.
- E. They can increase the cluster size of the SQL endpoint.
Answer: A
NEW QUESTION # 30
Which of the following benefits is provided by the array functions from Spark SQL?
- A. An ability to work with complex, nested data ingested from JSON files
- B. An ability to work with time-related data in specified intervals
- C. An ability to work with data in a variety of types at once
- D. An ability to work with data within certain partitions and windows
- E. An ability to work with an array of tables for procedural automation
Answer: D
NEW QUESTION # 31
Which of the following must be specified when creating a new Delta Live Tables pipeline?
- A. A key-value pair configuration
- B. A location of a target database for the written data
- C. At least one notebook library to be executed
- D. A path to cloud storage location for the written data
- E. The preferred DBU/hour cost
Answer: C
Explanation:
Explanation
https://docs.databricks.com/en/delta-live-tables/tutorial-pipelines.html
NEW QUESTION # 32
In which of the following scenarios should a data engineer select a Task in the Depends On field of a new Databricks Job Task?
- A. When another task needs to successfully complete before the new task begins
- B. When another task needs to fail before the new task begins
- C. When another task needs to use as little compute resources as possible
- D. When another task needs to be replaced by the new task
- E. When another task has the same dependency libraries as the new task
Answer: A
NEW QUESTION # 33
Which of the following statements regarding the relationship between Silver tables and Bronze tables is always true?
- A. Silver tables contain more data than Bronze tables.
- B. Silver tables contain a less refined, less clean view of data than Bronze data.
- C. Silver tables contain less data than Bronze tables.
- D. Silver tables contain aggregates while Bronze data is unaggregated.
- E. Silver tables contain a more refined and cleaner view of data than Bronze tables.
Answer: E
Explanation:
Explanation
https://www.databricks.com/glossary/medallion-architecture
NEW QUESTION # 34
A data engineer has a Job that has a complex run schedule, and they want to transfer that schedule to other Jobs.
Rather than manually selecting each value in the scheduling form in Databricks, which of the following tools can the data engineer use to represent and submit the schedule programmatically?
- A. There is no way to represent and submit this information programmatically
- B. pyspark.sql.types.DateType
- C. datetime
- D. Cron syntax
- E. pyspark.sql.types.TimestampType
Answer: D
NEW QUESTION # 35
A data engineer has realized that they made a mistake when making a daily update to a table. They need to use Delta time travel to restore the table to a version that is 3 days old. However, when the data engineer attempts to time travel to the older version, they are unable to restore the data because the data files have been deleted.
Which of the following explains why the data files are no longer present?
- A. The DELETE HISTORY command was run on the table
- B. The TIME TRAVEL command was run on the table
- C. The OPTIMIZE command was nun on the table
- D. The HISTORY command was run on the table
- E. The VACUUM command was run on the table
Answer: A
NEW QUESTION # 36
A data engineer that is new to using Python needs to create a Python function to add two integers together and return the sum?
Which of the following code blocks can the data engineer use to complete this task?
- A.
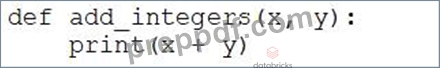
- B.

- C.

- D.

- E.

Answer: E
Explanation:
Explanation
https://www.w3schools.com/python/python_functions.asp
NEW QUESTION # 37
A data engineer has realized that the data files associated with a Delta table are incredibly small. They want to compact the small files to form larger files to improve performance.
Which of the following keywords can be used to compact the small files?
- A. REDUCE
- B. OPTIMIZE
- C. REPARTITION
- D. VACUUM
- E. COMPACTION
Answer: B
Explanation:
Explanation
OPTIMIZE can be used to club small files into 1 and improve performance.
NEW QUESTION # 38
A data architect has determined that a table of the following format is necessary:
Which of the following code blocks uses SQL DDL commands to create an empty Delta table in the above format regardless of whether a table already exists with this name?
- A. Option C
- B. Option A
- C. Option E
- D. Option B
- E. Option D
Answer: C
NEW QUESTION # 39
Which of the following Structured Streaming queries is performing a hop from a Silver table to a Gold table?
- A.

- B.

- C.
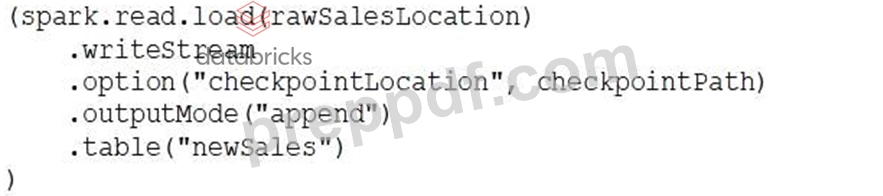
- D.

- E.

Answer: B
NEW QUESTION # 40
......
To become a Databricks Certified Data Engineer Associate, candidates must pass a rigorous exam that tests their knowledge of Databricks architecture, data modeling, data processing, and data integration. Databricks-Certified-Data-Engineer-Associate exam consists of 60 multiple-choice questions and must be completed within 90 minutes. Candidates must score at least 70% to pass the exam and earn the certification.
Certification Topics of Databricks-Certified-Data-Engineer-Associate Exam PDF Recently Updated Questions: https://passcertification.preppdf.com/Databricks/Databricks-Certified-Data-Engineer-Associate-prepaway-exam-dumps.html